 (※写真はイメージです/PIXTA)
(※写真はイメージです/PIXTA)
古文書の“くずし字”をAIが解読

最後は、古文書の解読にAIを活用する事例です。
熊本大学とTOPPANは、歴史資料「細川家文書(ほそかわけもんじょ)」の“くずし字”で書かれた約5万枚の未解読の古文書を、文書画像に含まれる文字を読み取ってテキストデータに変換するソフトウェア「AI-OCR」で解読する試みを実施。2024年7月に、AIが専門家でも解読が困難な難易度の高いくずし字を解読し、約950万文字のテキストデータを生成することに成功したと発表しました。
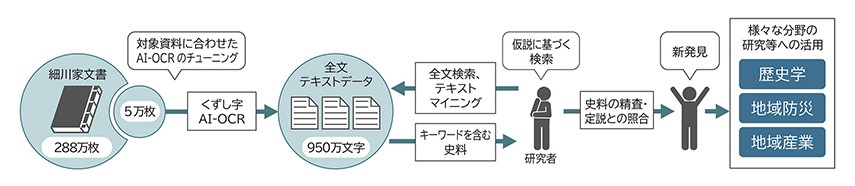
細川家文書とは、江戸時代に小倉藩主・熊本藩主をつとめた細川家に伝来した約288万枚の歴史資料群です。今回解読の対象となったのはそのうち、細川家奉行所の執務記録「奉行所日帳(ぶぎょうしょにっちょう)」や藩主細川忠利の口頭での命令を日次に記録した「奉書(ほうしょ)」、さらに「御国御書案文(おくにごしょあんもん)」「方々(かたがた)への状控(じょうひかえ)」など約5万枚の古文書でした。
解読に活用されたAI-OCRは、蓄積した字形データベースをAIに学習させることで精度を高めていく仕組みで、TOPPANでは2014年から「くずし字AI-OCR」技術の研究を開始していました。同社が独自開発したくずし字AI-OCRは、学習データの質と量が他社製品より高く、搭載されているAIモデルが優秀であることなどを特徴としており、今回の取り組みでは、TOPPANグループが開発したくずし字AI-OCRエンジンに古文書を読み込ませることで、約5万枚、約950万文字もの全文テキスト化に成功しました。
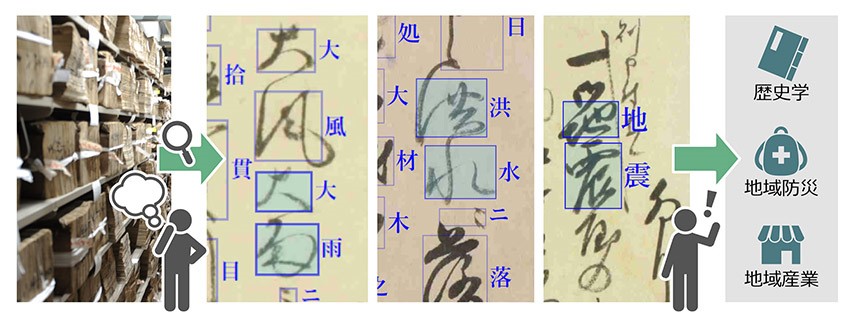
さらに、解読システムと連動するキーワード検索システムを構築したことで、江戸時代前期の細川藩領国の約90年間にわたる社会的事件や統治制度の変容を示す記述を含んだ資料の検索収集が可能に。実際に、くずし字AI-OCRで作成したテキストデータに対して「地震、大雨、洪水、虫、飢、疫」などの災害に関連するキーワードで検索・調査した結果、300件以上の記述を発見したとのことです。
TOPPANでは今後、グループ会社のTOPPANデジタル、TOPPANエッジとも連携してAI-OCRによる古文書解読支援システムの精度向上を目指すとともに、全国の教育機関、博物館・資料館、地方自治体と提携して、全国各地に眠る貴重な歴史的資料の研究・活用の支援に取り組んでいく考えを明かしています。AIを活用する同社の取り組みにより、これまで解読されていなかった、日本国内に数十億点以上残存すると言われているさまざまな古文書の内容が明らかになる日も近いかもしれません。
写真の分析、地図の解析、古文書の解読……これまで見てきたように、考古学の分野でもAIを活用したさまざまな取り組みが進んでおり、著しい成果をもたらしています。これまで未発見だった遺跡を発見し、判読できなかった文書を解明するAIは、今後も研究者のよき相棒となり、考古学における課題を次々に解決してくれる可能性が高いと言えるでしょう。次はどのような謎を解き明かしてくれるのか、AI活用による“新発見”を楽しみに待ちたいと思います。
-----------------------------------------------------
<プロフィール>
カワハタユウタロウ
フリーライター。大学卒業後、編集プロダクション勤務を経て、Eコマース・通販関連業界紙の編集部に約7年間所属。その後、新聞社系エンタメニュースサイトの編集部で記者として活動。2017年からフリーランスのライターとして、エンタメ、飲食、企業ブランディングなどの分野で活動中。

