

人間と変わらない自然な言語での返事を可能にするLLM
梅津氏に話を伺ったのは、顧客との価値共創活動の拠点である「RICOH BUSINESS INNOVATION LOUNGE TOKYO」。リコーの強みである顧客接点力を生かした、100以上ある各業種の顧客価値シナリオと、自然言語処理や空間認識分野に強みを持つリコー独自のAI技術を掛け合わせ、価値提供事例を顧客企業と共創するといいます。
リコーは現在、主力の複合機などに加えてデジタルサービスの事業強化を図り、ビジネスプロセスオートメーション(BPA)領域とコミュニケーションサービス(CS)領域の2つを成長領域と定めています。この2領域を進化させていくうえで重要になるのがAIの活用です。
AI技術は驚くほどのスピードで進化していますが、昨今、話題になっているのが大規模言語モデル(LLM)。リコーもいち早くLLMを活用した独自のAIを開発してきました。
LLM(Large language Models)とは、大量のデータとディープラーニング(深層学習)技術によって構築された言語モデルのことをいいます。言語モデルとは、文章や単語の出現確率をモデル化したもので、AIによる文章作成などの自然言語処理で用いられています。実際に、ChatGPTやGoogle、Bingなどで検索をしたときに、入力した質問に対して人間のように自然な言葉で答えてくれるのを多くの人が経験しているでしょう。
「それは、莫大な量の言語情報を学習したAIが、ユーザーの質問に対し自然な言語で返答してくれているものです。言語を学習したLLMは、文章の中で離れた単語の関係までを把握し、文脈を考慮した処理が可能で、自然文の質問への回答や文書の要約といった処理を人間並みの精度で実行できます」
昨今、労働人口の減少や高齢化を背景に、AIを活用した生産性向上や付加価値の高い働き方が企業成長の課題となっており、多くの企業がその解決の手段としてAIの活用に注目しています。しかしながらAIを実際の業務に適応させるには、その企業固有の用語や言い回しなどを含む大量のテキストデータをLLMに学習させ、その企業独自のAIモデル(カスタムLLM)を作成することが不可欠だといいます。
「ChatGPTを使ったときに、WEBに出ている情報は答えてくれるけど、自分が本当に知りたい情報は出てこないという経験が、おそらく誰にでもあるでしょう。ChatGPTはすごく便利な一方で、企業が持っている特許や公開してない技術情報などは出てきません。しかし、それらも含めてChatGPTのように上手に回答してくれると、業務を遂行する上でとても便利です。そこで、当社では企業固有の用語や言い回しなどを含む大量のテキストデータを学習させることで、その企業独自のAIモデル(カスタムLLM)を作成することを目指しています」

現実の業務で活用できるLLMを実現
では、リコーが開発しているLLMの強みは、どのようなところにあるのでしょうか?
「企業のデータに対して最も効率よく学習して、適切に答えられるようにするのが目標です」
AIプラットフォームにある企業のデータを学習させていくと、その企業向けにチューニングされていきます。しかし、学習計画が適正でないと逆に一般的な用語に対応できなくなり、ユーザーが望んでいるような回答を得られなくなります。今回、同社が開発したLLMは、米Meta Platforms社が提供する「LLM Llama2-13B」をベースに、日本語と英語のオープンコーパスを追加学習させています。コーパスとは、自然言語の文章や使い方を大規模に収集した一般公開されているデータセットのこと。同社では、利用するコーパスを厳選したうえで、誤記や重複の修正などのデータクレンジングを行い、学習データの順序や割合を最適化するカリキュラム学習をさせるなど、独自の工夫が組み込まれています。
「その結果、学習内容が最適化されて、一般用語も理解しながら企業用語も覚えているというような、現実の業務で活用できるLLMを実現しました」
事実として同社のLLMは、日本語LLMの性能評価で広く使われている日本語ベンチマークツール(LLM-jp-eval)を用いたほかのLLMモデルとの性能比較で、評価スコアの平均値が最も高く、特にNLI(自然言語推論能力)において高性能となっているなど、優れた性能を確認しています。
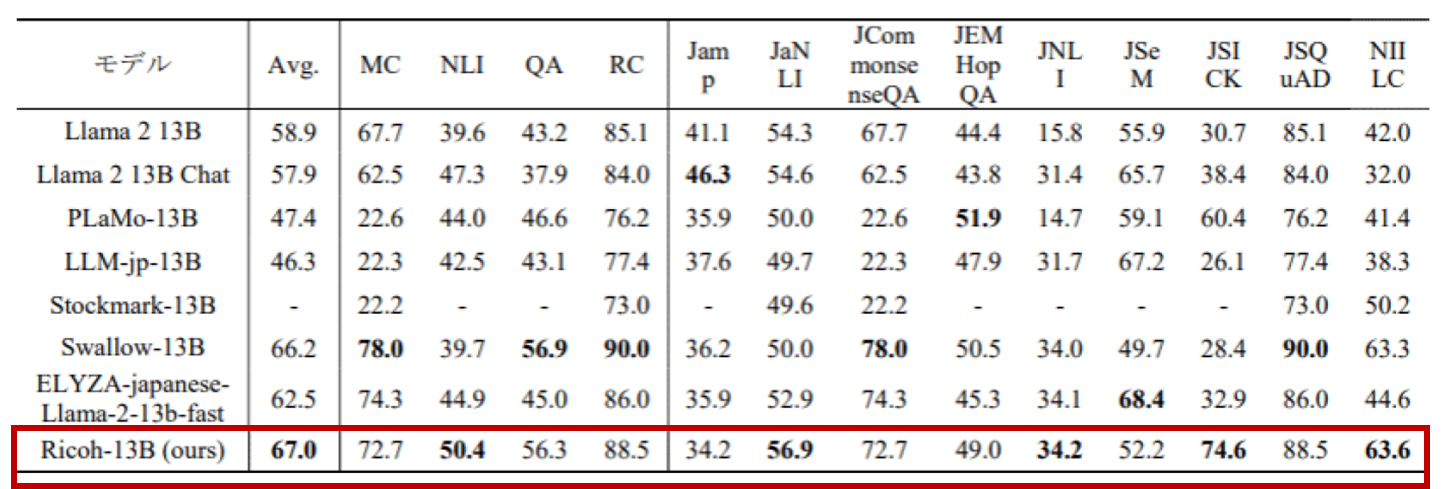
MC、NLI、QA、RCは、下記カテゴリー内の平均値。
Avg.はその4カテゴリー平均値の平均値。
MC(Multi-Choice QA:多肢選択質問応答):jcommonsenseqa
NLI(Natural Language Inference:自然言語推論):jamp、janli、jnli、jsem、jsick
QA(Question Answering:質問応答):jemhopqa、niilc
RC(Reading Comprehension:読解):jsquad
「企業には『FAQに使いたい』『複雑な論文の問い合わせをしたい』など、AIでやってみたいことはいろいろあると思います。それを実現するためには、希望に合わせてLLMを学習させる必要があります。当社は、それぞれの企業に希望を伺ったうえで最適な学習カリキュラムを設計し、十分な性能が出せるようにしたい。それが実現できると証明できたのが、このベンチマークによる結果だと考えています」
社員一人ひとりに秘書がつく…カスタムLLMで描く未来
近年になってChatGPTが登場し、一般的なものであればAIと会話をしながら自分のほしい情報が得られるようになりました。加えて、これまで説明してきたカスタムLLMであれば、企業内データも活用できるようになります。
「当社では、いずれはAIエージェントという形で、人と自然に会話をするように自分の必要な情報が得られるようなところに持っていきたいと考えています」
実際に、同社は昨年AIエージェントを公開しました。AIエージェントは、こちらが話しかけたことを音声認識し、LLMを駆使して内容を理解・分析した上で音声発話で返事をしてくれます。顧客からの要望に対して企業ができることをAIエージェントが提案してくれたり、契約書の内容について相談をすれば、AIエージェントがリスクを指摘してくれたりするなど、業務をより効率的に進められるようになります。
「皆さんの一人ひとりに秘書がつく。社内的にはAIエージェントを『デジタルバディ』と呼んでいますが社内のすべての文章や個人が受け取るメールなどのデータを『デジタルバディ』が把握していて、何かを聞いたら的確に返事をしてくれる。『デジタルバディがリアルの人間と協調して仕事を進めるような未来を実現したいと考えています」

【問合せ先】
「仕事のAI」事務局:zjc_shigoto-ai@jp.ricoh.com
